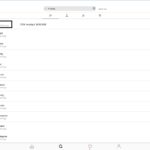
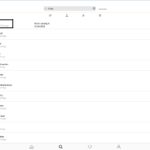
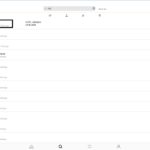
Diverse Überlegungen, Gespräche und Dateninterpretationsideen ergaben die Notwendigkeit der Einführung sog. „Themenwelten“. Die aktuelle Version der Auswertungssoftware erlaubt nun den Auswurf von Überblickstabellen.
Beispiele:
(1) Datenschau nach vordefinierten Locations
-> Suche nach dem Substringschema
themenwelt_loc_ueberblick.xlsx
(2) Datenschau nach vordefinierten Tags|Terms
-> Suche nach dem Substringschema UND Suche nach dem genauen Ausdruck
themenwelt_tags_ueberblick.xlsx
Die verlinkten Beispiele sind Probedatenauszüge, um u.a. auch die Performance zu testen.
ToDo für die Versionsnummer 0.10Beta:
(1) Zielgruppenidentifikation nach folgenden Fragesschemata (Übersetzung in SQL folgt).
(a) Welche Gruppen sprechen in [Ort] über [Tag 01|Tag02|Tag03]?
(b) Welche Gruppen springen von [Ort 01] zu [Ort 02]?
(b) Welche Gruppen springen von [Ort 01] zu [Ort 02] und sprechen über [Tag 01|Tag02|Tag003]?
(2) Aktivierung der Beliebtheitsindikatoren für die Datenschau.
(a) Welche Tags sind beliebt?
-> Einbeziehung der Likes und Comments in Form der Zahlen.
-> (Er)findung eines geeigneten Bewerungssystems auf Basis der Nutzwertanalyse.
(b) Welche Orte sind beliebt?
-> siehe (a)
-> Erweiterung um die Begutachtung der Postzeitstempel.