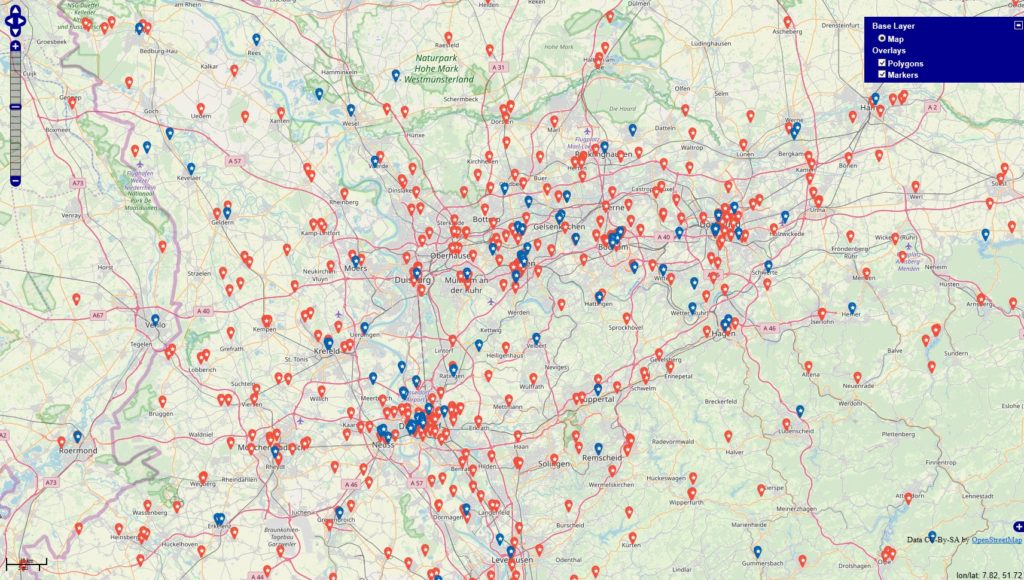
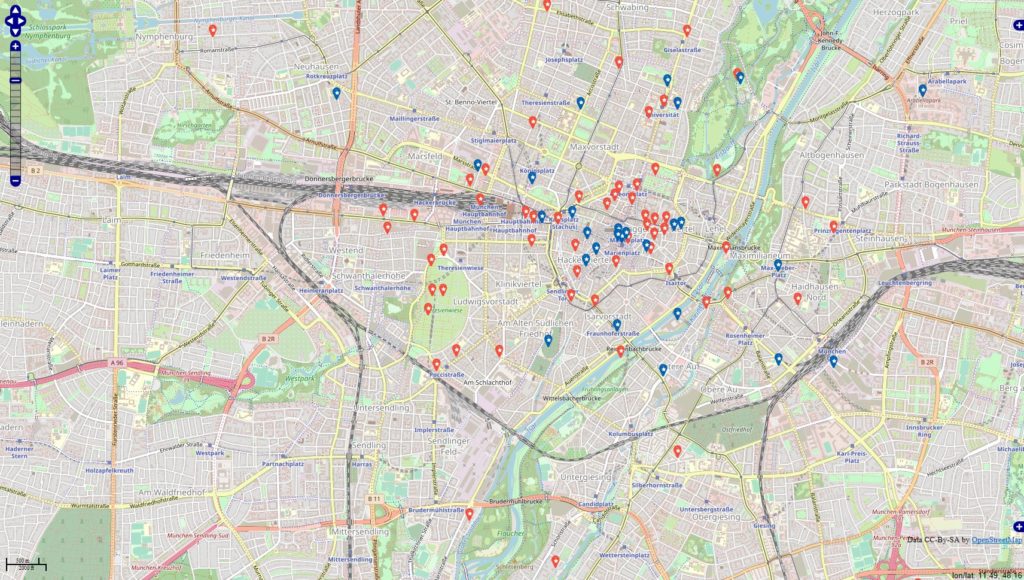
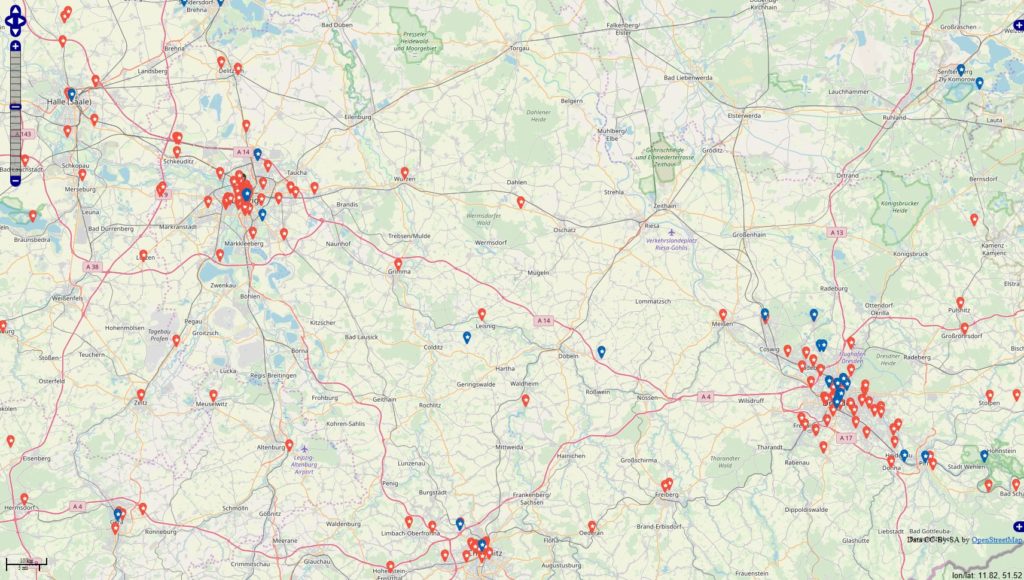
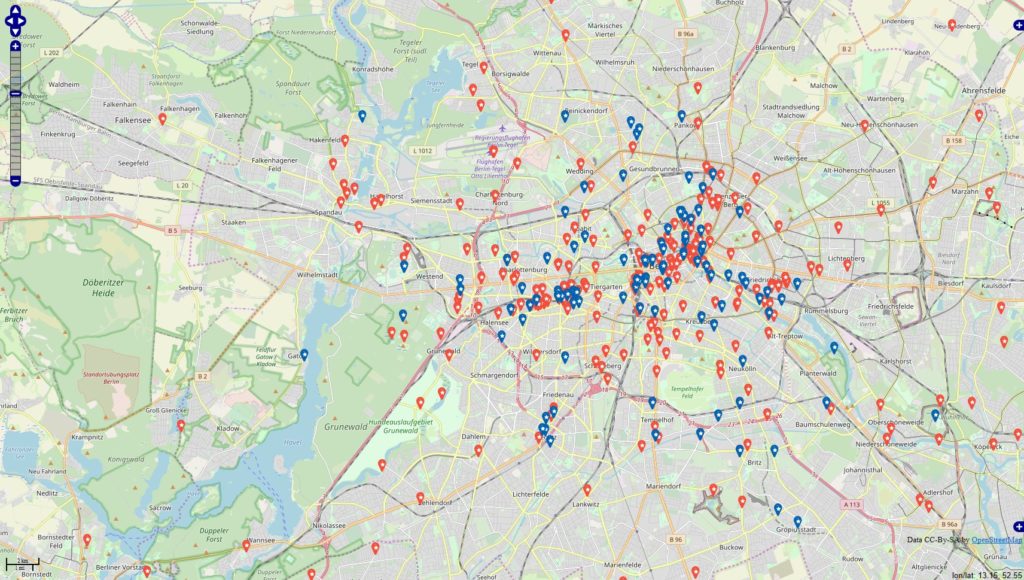
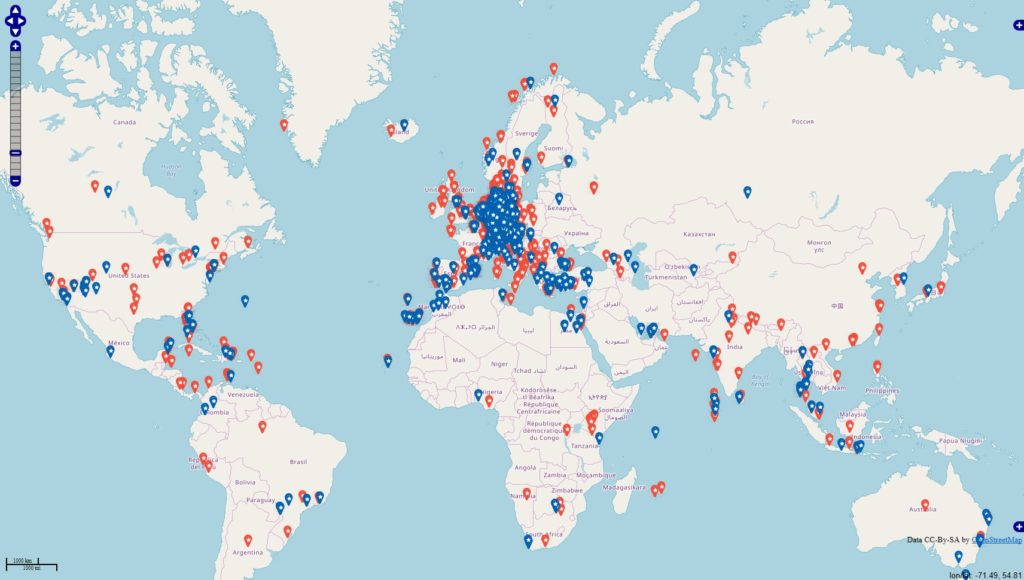
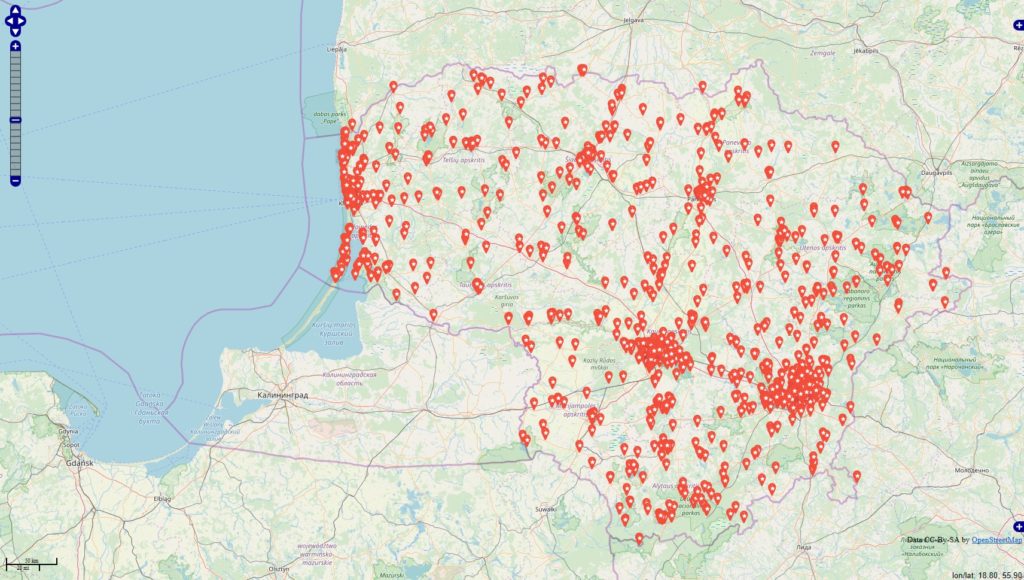
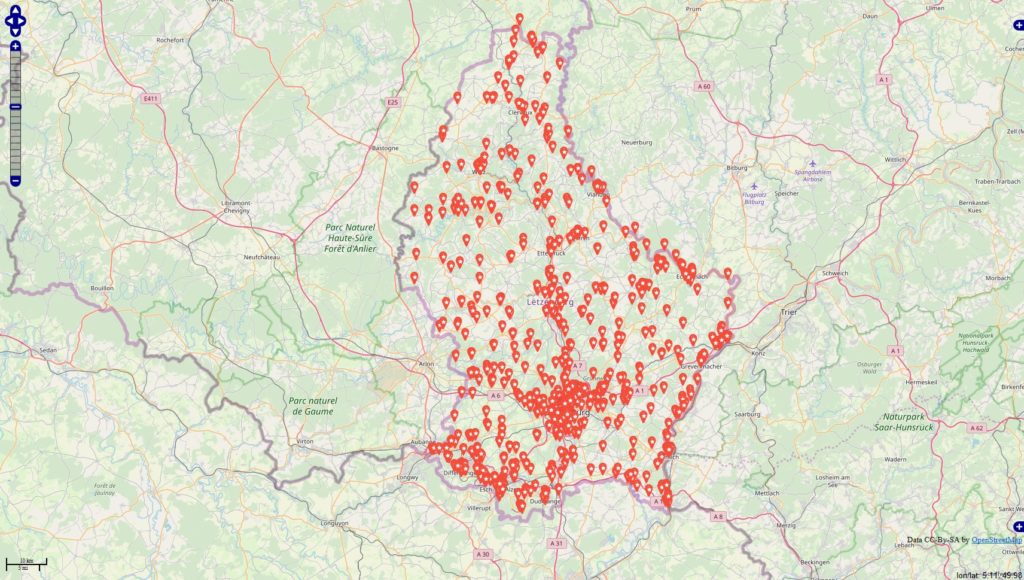
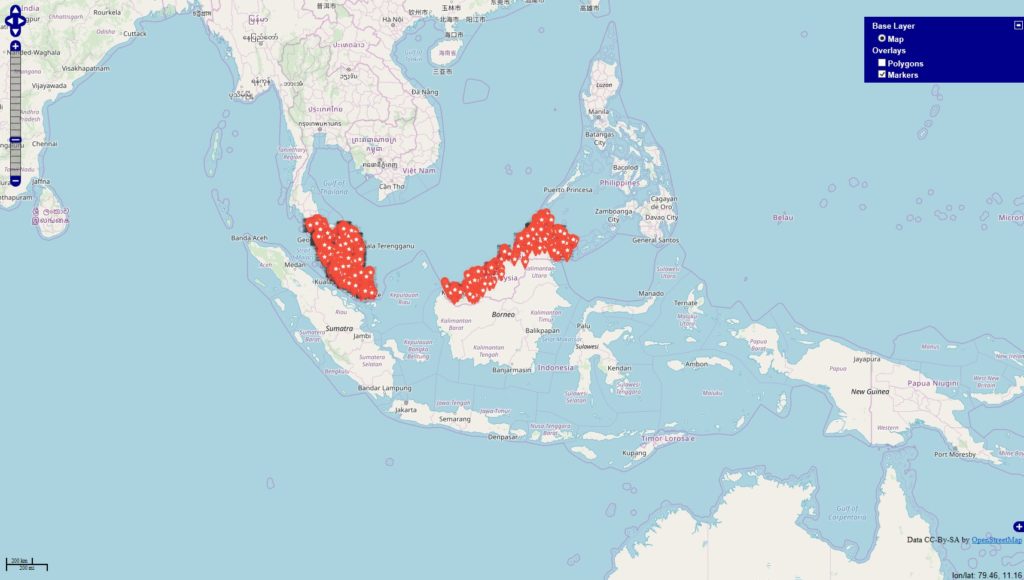
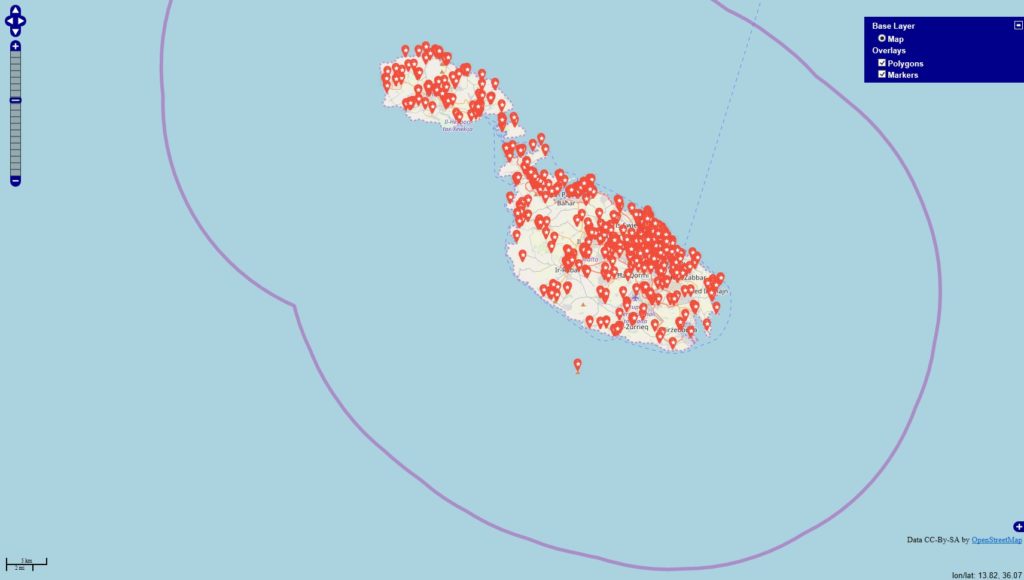
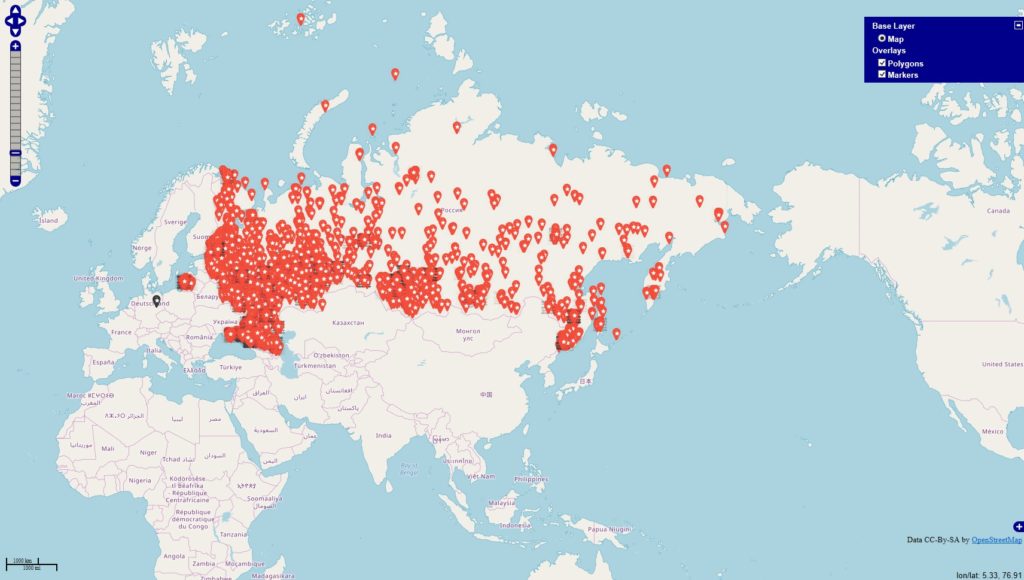
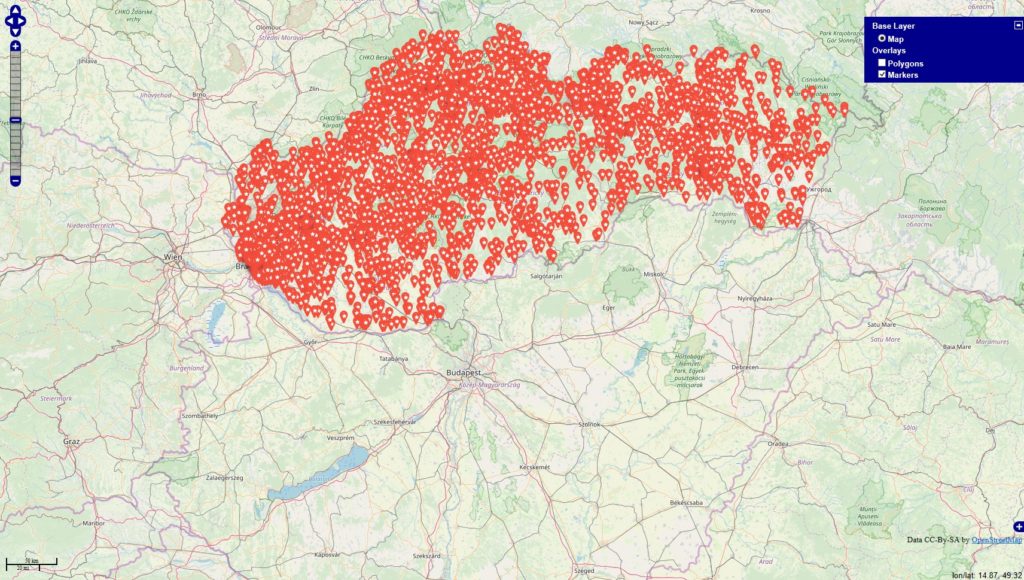
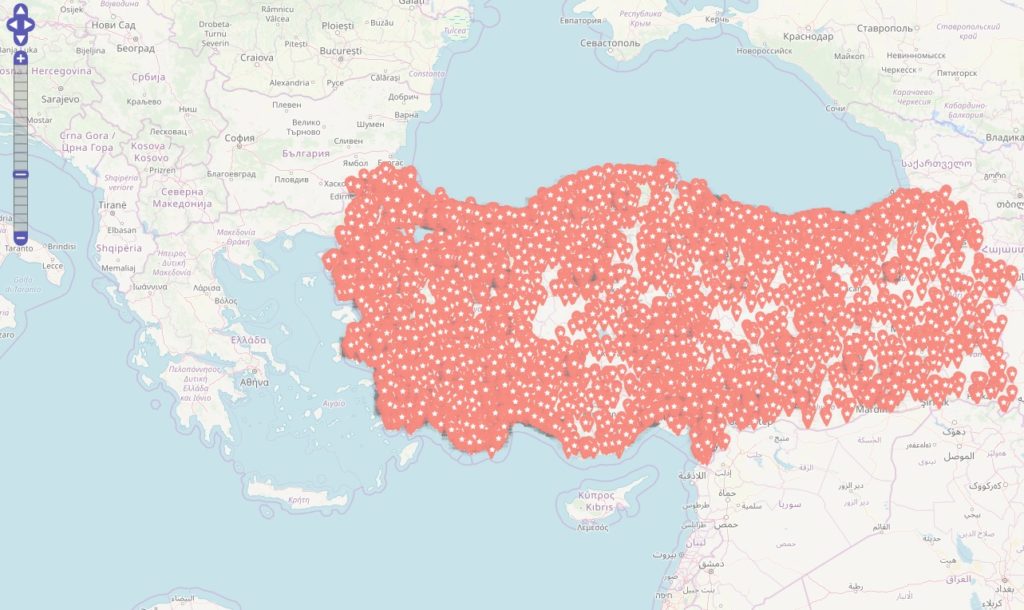
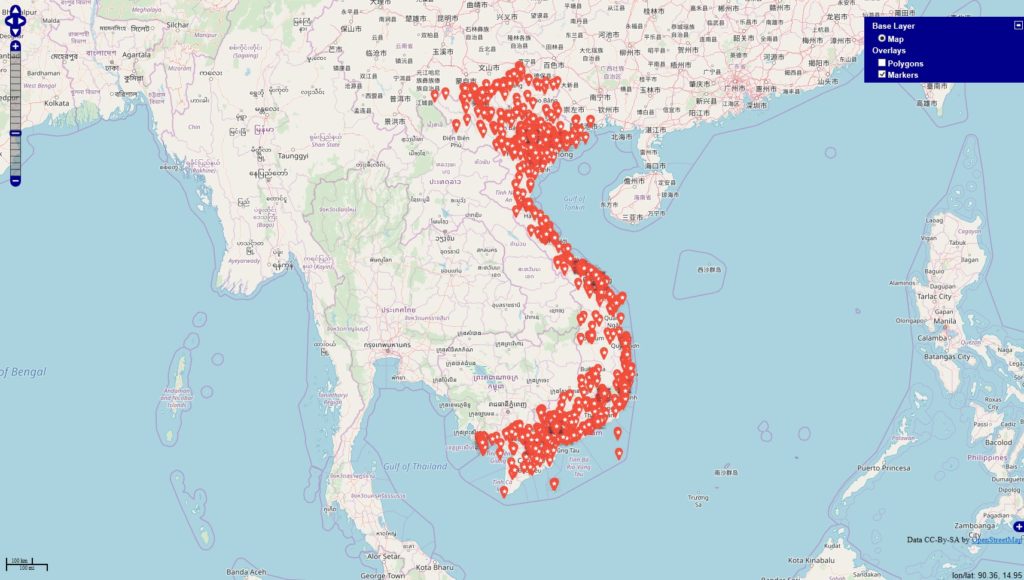
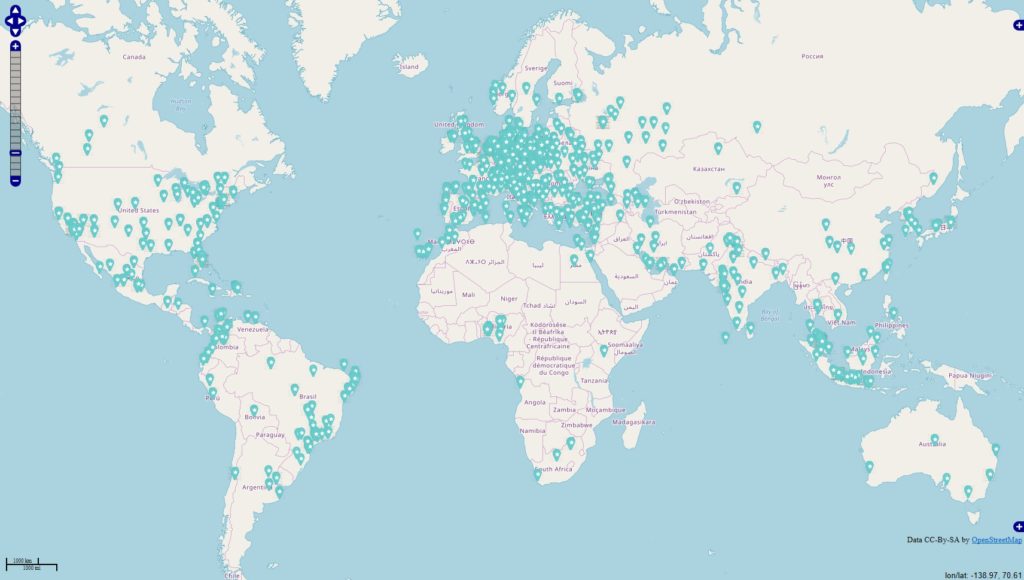
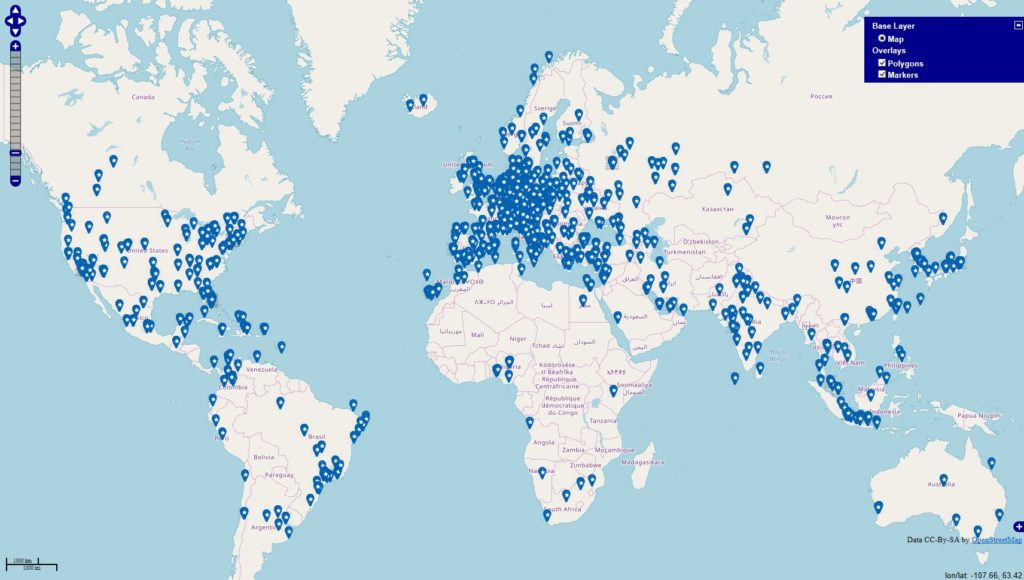
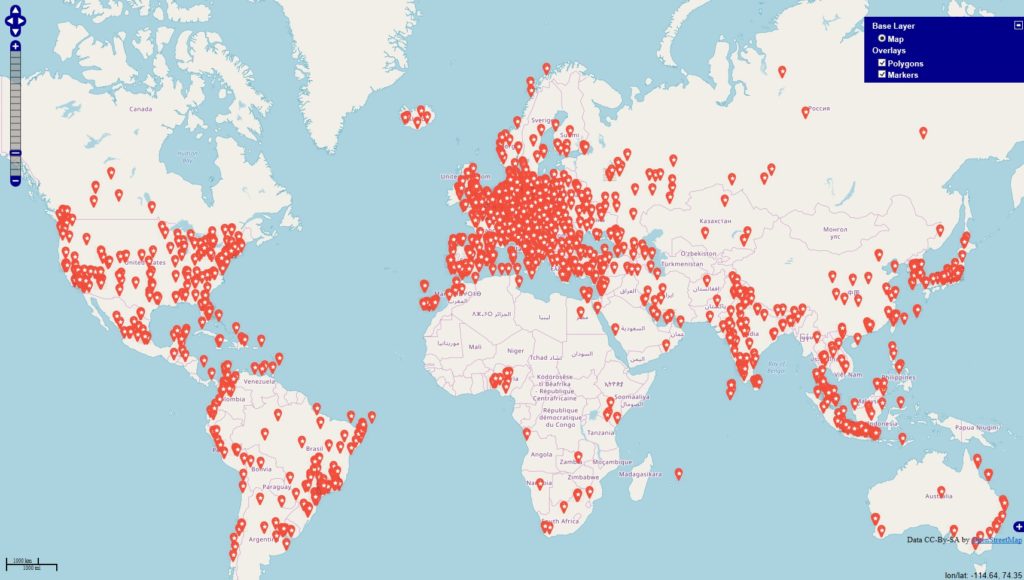
Inspiriert von einigen Diskussionen befragte ich die Datenbanken
#werbung -> 4945 Orte (rot)
#anzeige -> 1324 Orte (blau)
Datenbankstand: 13.06.2019 mit Filter auf Jahr 2018 + 01.01-13.06.2019 Filter für die Darstellung: mind. 10 Postings zu den Themen je Locations.
Im Datenbestand befinden 343067 Locations, die mit Deutschland via OSM-Abgleich eindeutig in Verbindung stehen. Es fällt auf, dass sich die Tags / Themen überschneiden u. das sehe ich in den Datensätzen in der Form, dass die Tags gleichzeitig in den Beiträgen genannt werden.
Wegen der starken Überschneidung der Themenwelten fasste ich die Ergebnisse zusammen und komme auf ~800.000 Beiträge von aktuell erfassten 70 Mio Beiträge mit Status „Weltweit“.
Tiefensichtung der Zahlen
Erfasste u. cod. Accounts: 25.061 von 1.538.231 aus Land „DE“
Erfasste Themen/Tags(wolken): 64.667 von 4.463.435 aus Land „DE“
Erfasste unique Bildinhalte: 5328 von 89.113 aus Land „DE“.
Erfasste Zeitstempel(Postings): 75.373 von 5.092.791 aus Land „DE“
Interaktionen
Likes: 21.231.617 von 714.917.463 Comments: 879.852 von 25.176.657
Die Sichtung lässt mich vermuten, dass Influencermarkting zwar eine pragmatische Spielart im Marketingmix ist u. natürlich auch bleibt (viele Indikatoren sprechen dafür …), jedoch dass diese Strategie künstlicher Hype ist. Ich denke in diese Richtung, weil die Kommunikation zu den genannten Themen im Vergleich zum „Grundrauschen“ zwar da ist, aber einen relativ kleinen Teil zeigt. Als Fazit würde ich Influencermarketing nicht verteufeln, sondern extrem punktgenau die Vor- u. Nachteile der jeweiligen Partnerschaften (Reichweite, provozierte Interaktionen, Ziele) analysieren u. hier auf gar keinen Fall schwammigen Begriffen wie „Erfahrung“, „Authentizität“ vertrauen … denn … es kommt letztendlich auch nur auf die Zahlen an.