Eine potentiell spannende Option liefert KNIME.
Kategorie-Archiv: KI – Anwendungen & Szenarien
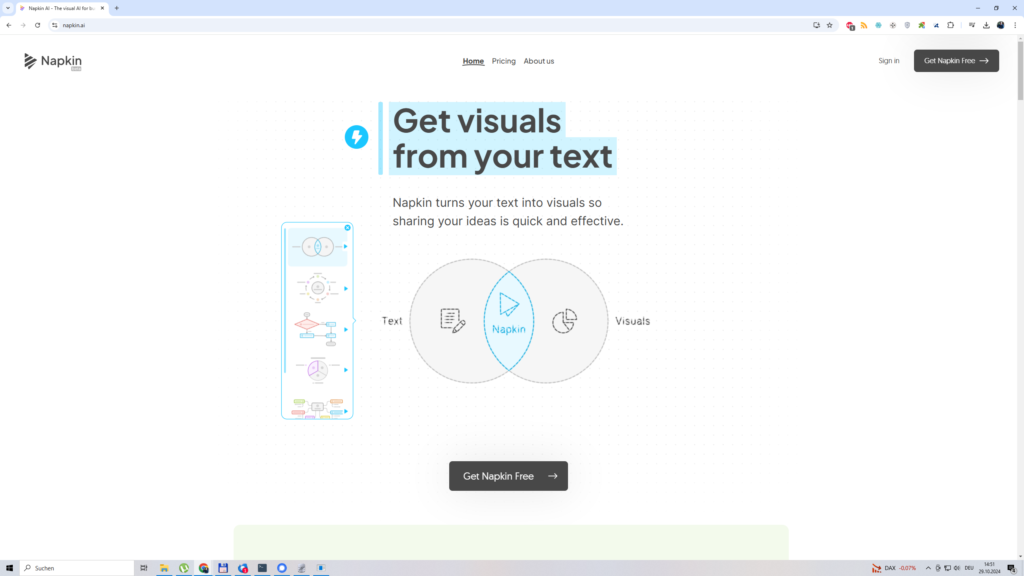
Wie kann ich extrem schnell schöne Grafiken auf Basis eines Textes mit KI erstellen?
Ein hochgeschätzter Kunde / Kontakt kippte bei mir erst heute einen interessanten Fall ein. Der sieht so aus: „Lieber Johannes, ich habe hier einen Text mit technischen Inhalten und da brauche ich unbedingt / ganz schnell schöne Grafiken!“ + „Bitte besorge mir eine Lösung!“
Die Lösung ist simpel und die nennt sich „napkin.ai„. Hier besorgt man sich einen Account (via Google bspw.) und man wird direkt auf eine Fläche, die einen an WordPress erinnert, umgeleitet.
Kling-AI, der letzte Generator aus der Testreihe
Diese Plattform entdeckte ich eher zufällig in den Untiefen von X (Twitter). Beim Testen bespiele ich solche Systeme immer mit zufällig ausgewählten Motiven aus meinem Bestand (i.d.R. Analogscans).
Fazit zu diesem Generator. Im Vergleich zu den anderen Produkten, ist das System ziemlich schlecht. Ich sehe diverse Bugs und gerade die Darstellung von Händen muss zwingend notwendig sauber erfolgen. Sicherlich werde ich das System für kreativere Anwendungen verwenden, oder in die Beobachtung legen. Allerdings eher nicht im Livebetrieb für Marketingzwecke.
LumaLabs – ein Generalist für die Videogenerierung
Der erste Generator, der mir aufgefallen ist, ist LumaLabs. Im Grunde ist hier die Qualität wieder vom Ausgangsmaterial und / oder der Qualität der Arbeitsanweisung (Prompt) abhängig. Die Generierung der Videos kann extrem lang dauern und ich empfehle eine Einbindung und Verwendung, wenn eine Unterfütterung von SocialMedia-Accounts geht. Die Videos lassen sich verlängern und teilweise ist die „Storyline“ durchaus sehr gut.
Hier ein paar Beispiele:
Es sind die üblichen „Bugs“, wie Augen, erkennbar und die Grundlage für die 3 Proben sind hier Analog-Scans (Basis: Lith-Abzüge auf Orwo) und generierte Bilder (Stable Diffusion + Analoglora)
Experimente mit Vertonungen – Gesichtsanimationen
Ein interessantes Werkzeug für diesen „Case“ ist Hedra und diese Plattform ist in der Basis-Variante kostenfrei, erlaubt bis zu 30 Sekunden Vertonung. Es stehen einige Standardstimmen zur Auswahl (in dem Beispiel ist es die Charlotte) und es lässt sich auch etwas Eigenes via Mikro da einspielen. Die Qualität des Videos (Hinweise: Augen, Bewegungen, Mimik und Gestik) ist von Ausgangsmaterial abhängig. Je besser die Kontraste und die Auflösung ist, desto besser ist eben auch das Endresultat.
Bei dem Beispiel wählte ich eine virtuelle Person – generiert via StableDiffusion unter Einbindung eines unserer AnalogLoras.
Experimente mit der Simulation von Emotionen (KI)
Vor einigen Tagen triggerte mich eine große Debatte rund um einen sog. „KI-Influencer“ und das führte dazu, dass ich eine spezielle Testreihe mit „Hailou“ anlegte.
Schritt 1.) Einen Account auf der Plattform anlegen.
Schritt 2.) Ein gutes Foto (Portrait etc.) suchen und da hochladen.
Schritt 3.) Definieren von Prompts und Videogenerierung.
Beispiele:
„amorous facial expression, conversation“
„sad facial expression, conversation“
„frustrated facial expression, conversation“
Hinweise und Gedanken:
- Nimm extrem gute und kontrastreiche Fotos.
- Die Plattform erlaubt (derzeit) keine Erweiterung der Videos auf >5 Sekunden
- Die Performance / die Qualität ist definitiv abhängig von der Qualität der Fotos.
- Die Resultate zeigen die typischen „Bugs“ (Augenform und Hände).
Viel Spaß beim Experimentieren.
Freigabe: neues Lora für die BildGenerierung (KI)
Die Trainingsdaten basieren auf einige meiner Analogfilme, die ich mit Hilfe der Technik „PeeSoaked“ kunstvoll modifizierte.
URL (Download): https://civitai.com/models/502769/soakedpee
Deepfakes erkennen – Teil 3
Etwas komplizierter war und ist die Analyse von Deepfake-Videos. Hierbei experimentierte ich mit verschiedenen Ansätzen, wie Fraktalanalysen und der interessante Analyseweg ist die Prüfung auf der Pixelebene.
Beispiele „Deepfakes“


Beispiel „Kein Deepfake“

Die Analyseidee kam mir nach der Sichtung extrem vieler Video-Deepfakes. Hier fand ich bei personengebundenen Werken 2 Auffälligkeiten: (1) ein Austausch des Gesichtes und (2) ein Austausch der Mund- und Lippenareale.
In extrem vielen Fällen sind die Resultate sehr schlecht und relativ zügig erkennbar, in wenigen Fällen war die „manuelle“ Erkennung durchaus etwas komplizierter. Jedoch ist mir aufgefallen, dass die manipulierten Areale leicht „wackeln“ und hinsichtlich der Bewegungsabläufe leicht oder sehr stark unlogisch sein können.
Der Weg der Pixelanalyse kann Manipulationen visualisieren und hier fallen einige spannende Sachen auf: Deepfakes produzieren „matschige Areale“, die Gesichtskonturen verschwimmen und das liegt daran, dass bei den analysierten Proben die manipulierten Areale sich nicht im Kontext zum Gesamtwerk „bewegen“.
Deepfakes erkennen – Teil 2
Eine weitere potentiell spannende Deepfake-Erkennungsoption ist die Analyse der Datensätze. Hier gehe ich über 2 Wege vor:
(1) Die Prompts
Im Grunde ist das simpel zu erklären. Man besorgt sich Zugänge zu den relevanten Online-Generierungsdiensten (bitte selbst recherchieren, oder bei uns anrufen!) und testet die wichtigen + wichtigeren „Checkpoints“ via Prompt so durch: „instagramphoto, [Name der Person]“ und prüft da die Resultate.
Man kann das manuell oder maschinell realisieren und ich fand bei beiden Varianten nicht nur die üblichen Prominenten, Schauspieler:innen und Politiker:innen (teilw. weltweit), sondern auch kleine + große Influencer:innen (TikTok, Instagram und LinkedIN).
Leider fand ich (noch) keine Gelegenheit, einen Workflow zu realisieren, welcher die Resultate der „Prompt-Variante“ daher nimmt, um die Rohdatenquellen zu identifizieren.
(2) Die Loras
Speziell auf der Plattform https://civitai.com/ lassen sich, nach meiner Prüfung, sogenannte „Loras“ finden, welche auf Basis öffentlicher Bilder von Promis, Politiker:innen (weltweit) und auch Schauspieler:innen generiert wurden. Diese Loras sind als „Mini-KI“ zu verstehen und lassen sich mittels Prompts in Verbindung mit den großen Datensätzen selbstverständlich verwenden.
Zusammengefasst:
Der Modus (1) und (2) beschreibt zwar nicht die Erkennung von Deepfakes auf Basis von vorgelegten Medien, allerdings habe ich die Rechercheoptionen in das „Tagesgeschäft“ überführt, weil die Existenz von Datenspuren (Modelle + Loras) im Grunde aussagt: „Man kann da Deepfakes erstellen“.
Deepfakes erkennen – Teil 1
Vor einigen Monaten sprach mich ein alter Geschäftskontakt und Freund auf diese Deepfakeproblematik an und ich fand endlich Gelegenheit, mir das Thema sehr genau anzuschauen. Wie ging ich hier vor? Die Antwort ist simpel: ich organisierte mir die Software „Automatic 1111“ inkl. aller relevanten Checkpoints (Daten) + Loras und generierte im ersten Schritt 50.000 Deepfakes. Hierbei wurde auf folgende Punkte geachtet:
- Generierung von Medien mit verschiedenen Qualitäten
- Promptaufbau auch mit Fokus auf Emotionen, Licht/Schatten-Effekte
- Generierung von Deepfakes mit Inhalt(en): alle Geschlechter, alle Altersgruppen, viele Millieu-Beispiele
Ich legte die besten Generierungen diversen Freund:innen zur Ansicht vor, um meine (!) Fehlinterpretationen zu bereinigen. Bei der Vorlage achtete ich sehr genau darauf, dass ich ausschließlich weibliche „normschöne“ Deepfakes (keine Aktfotografien) 2 Gruppen präsentierte:
- männlichen Freunden
- weiblichen Freunden
Hochspannend waren die Rückmeldungen aus der Gruppe (2) und ich hörte in vielen Gesprächen folgende Hinweise:
- „Da stimmt etwas nicht“
- „Die Personen haben keinen Charakter“
- „Die Personen haben keine Seele“
Die Gruppe (1) reagierte anders:
- „Wow“
- „Wo hast Du die Frau kennen gelernt?“
- …
Eigentlich witzig, hier noch einmal über die Ergebnisse meiner kleinen und natürlich unprofessionell durchgeführten „Marktforschung“ nachzudenken. Allerdings entschied ich mich, mich mit der Aussage „Die Personen haben keine Seele“ etwas intensiver zu beschäftigen und da die Augen ja der „Spiegel der Seele“ sind, war die Problemlösung „Deepfakeerkennung“ schnell geregelt.
Alle geprüften Deepfakes aus dem Pool der 50.000-Bilder zeigen diese Deepfake-Indikatoren:
- Deformierte Iris + Pupille
- leichte und starke Abweichungen der Iris + Pupillengröße bei beiden Augen
- leichte und starke Fehldarstellungen der Irisgestaltung (Bezug: ein Auge, beide Augen)
In dem Umfeld der Bildgenerierung existieren selbstverständlich extrem gut trainierte Daten und auch Loras, welche das Problem der (fehlerhaften) Augendarstellung lösen können, jedoch sind auch in den relevanten Experimenten die genannten „Bugs“ aufgefallen.
Wie sieht nun unser Ansatz aus? Wir sammeln noch ca. 150.000 weitere Deepfakes, trainieren eine sehr spezielle KI und geben das Resultat (DIE Daten, DIE KI) Mitte 2024 einem potentiell interessierten Publikum frei.
Wie kann man nun Deepfakes OHNE tiefergehendes technisches Wissen und Daten erkennen? Meine Ratschläge sind:
- Wenn es sich „komisch anfühlt“, stimmt mit dem Medium etwas nicht.
- Wenn das Medium zu glatt und zu professionell ausschaut und die Gestaltung nicht in den Kontext und die Story passt, stimmt etwas mit dem Medium nicht.
- Immer auf die Verbindung der Motive (Vordergrund, Mittelgrund, Hintergrund) achten, hier lassen sich auch manchmal Unstimmigkeiten erkennen.
- Interessant sind auch Leberflecken, Narben an untypischen Stellen im Gesicht / auf der Haut
- Unstimmigkeiten bei Zähnen / Zahndarstellungen liefern Hinweise auf Deepfakes






